.drop_duplicates()
sintassi
df.drop_duplicates() in base a tutte le colonne
df.drop_duplicates(subset=['colonna]) in base alla colonna indicata
df.drop_duplicates(subset=['colonna,colonna,...]) in base alle colonne indicate
df.drop_duplicates(subset=['colonna],keep='last') mantiene l'ultima riga invece della prima
colonna con gli indici
se nel usare il comando .drop_duplicates() si crea una colonna con gli indici
occorre usare il comando .reset_index(drop=True)
per rimuovere la colonna con gli indici
(veri Python - Dataframe - indice)
- rimuove duplicati .unique()
df["Product"].unique()
il comando riomuove però anche l'intestazione della colonna
in quanto é considerata come index
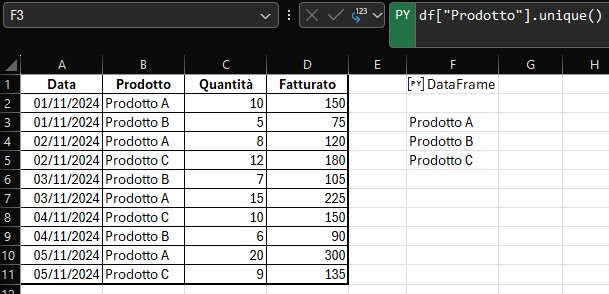
esempio: da una tabella faccio la lista unica dei prodotti
df["Prodotto"].unique()
- rimuovi duplicati mantenendo l'intestazione df[~df.duplicated()] per rimuovere i duplicati matenendo l'intestazione della colonna usa la sintassi
- conversione in set convertendo una colonna in una set
df[~df.duplicated()]
si rimuovono automaticamente i duplicati
(vedi Python - funzioni / metodi - variabili - liste - conversione)
variabile = set(df["colonna"])