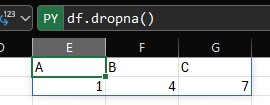
per rimuovere da un dataframe gli elementi errori NA
si usa il comando .dropna()
libreria Pandas
sintassi
df.dropna() rimuove le righe vuote
con parametri
df.dropna(axis=x, how='...', thresh=None, subset=None, inplace=False)
- axis= 0 righe (default) / 2 colonne
- how= any elimina la riga/colonna se almeno un valore è NaN (default) / all elimina la riga/colonna solo se tutti i valori sono NaN
- thresh= richiede un numero minimo di valori non-NaN per mantenere la riga/colonna
- subset= specifica un sottoinsieme di colonne da considerare per il controllo dei NaN
- inplace= True modifica il DataFrame originale senza restituirne una copia
colonna con gli indici
se nel usare il comando .dropna() si crea una colonna con gli indici ed alcuni numeri magari sono mancanti
occorre usare il comando .reset_index(drop=True)
per reimpostare gli indici e rimuovere la colonna con gli indici
(veri Python - Dataframe - indice)
esempio: creo a mano un dataframe e poi rimuovo in NAN
import pandas as pd
import numpy as np
df = pd.DataFrame({ dataframe manuale con elementi np.nan
'A': [1, 2, np.nan],
'B': [4, np.nan, np.nan],
'C': [7, 8, 9]})
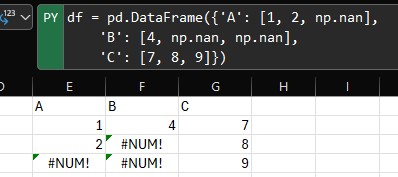
# Rimuove le righe con almeno un NaN
df.dropna()